N-BEATS#
In this notebook, we show an example of how N-BEATS can be used with darts. If you are new to darts, we recommend you first follow the quick start notebook.
N-BEATS is a state-of-the-art model that shows the potential of pure DL architectures in the context of the time-series forecasting. It outperforms well-established statistical approaches on the M3, and M4 competitions. For more details on the model, see: https://arxiv.org/pdf/1905.10437.pdf.
[1]:
# fix python path if working locally
from utils import fix_pythonpath_if_working_locally
fix_pythonpath_if_working_locally()
%matplotlib inline
[ ]:
# use darts plotting style
from darts import set_option
set_option("plotting.use_darts_style", True)
[2]:
import warnings
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from darts import TimeSeries, concatenate
from darts.dataprocessing.transformers import MissingValuesFiller, Scaler
from darts.datasets import EnergyDataset
from darts.metrics import r2_score
from darts.models import NBEATSModel
from darts.utils.callbacks import TFMProgressBar
warnings.filterwarnings("ignore")
import logging
logging.disable(logging.CRITICAL)
def generate_torch_kwargs():
# run torch models on CPU, and disable progress bars for all model stages except training.
return {
"pl_trainer_kwargs": {
"accelerator": "cpu",
"callbacks": [TFMProgressBar(enable_train_bar_only=True)],
}
}
[3]:
def display_forecast(pred_series, ts_transformed, forecast_type, start_date=None):
plt.figure(figsize=(8, 5))
if start_date:
ts_transformed = ts_transformed.drop_before(start_date)
ts_transformed.univariate_component(0).plot(label="actual")
pred_series.plot(label=("historic " + forecast_type + " forecasts"))
plt.title(f"R2: {r2_score(ts_transformed.univariate_component(0), pred_series)}")
plt.legend()
Daily energy generation example#
We test NBEATS on a daily energy generation dataset from a Run-of-river power plant, as it exhibits various levels of seasonalities
[4]:
df = EnergyDataset().load().to_dataframe()
df["generation hydro run-of-river and poundage"].plot()
plt.title("Hourly generation hydro run-of-river and poundage")
[4]:
Text(0.5, 1.0, 'Hourly generation hydro run-of-river and poundage')
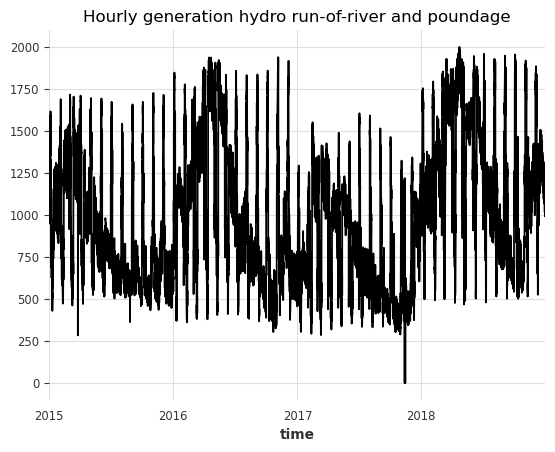
To simplify things, we work with the daily generation, and we fill the missing values present in the data by using the MissingValuesFiller:
[5]:
df_day_avg = df.groupby(df.index.astype(str).str.split(" ").str[0]).mean().reset_index()
filler = MissingValuesFiller()
scaler = Scaler()
series = filler.transform(
TimeSeries.from_dataframe(
df_day_avg, "time", ["generation hydro run-of-river and poundage"]
)
).astype(np.float32)
train, val = series.split_after(pd.Timestamp("20170901"))
train_scaled = scaler.fit_transform(train)
val_scaled = scaler.transform(val)
series_scaled = scaler.transform(series)
train_scaled.plot(label="training")
val_scaled.plot(label="val")
plt.title("Daily generation hydro run-of-river and poundage")
[5]:
Text(0.5, 1.0, 'Daily generation hydro run-of-river and poundage')
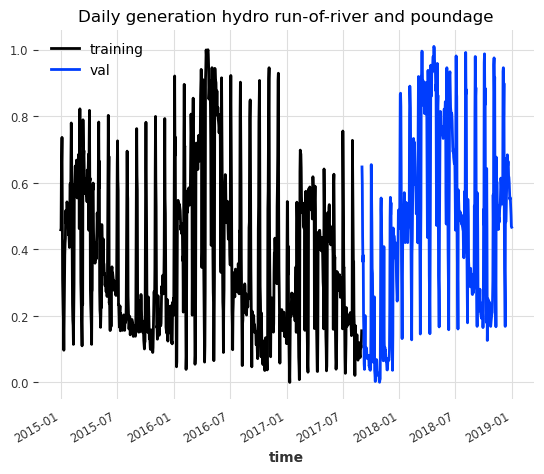
We split the data into train and validation sets. Normally we would need to use an additional test set to validate the model on unseen data, but we will skip it for this example.
Generic architecture#
N-BEATS is a univariate model architecture that offers two configurations: a generic one and a interpretable one. The generic architecture uses as little prior knowledge as possible, with no feature engineering, no scaling and no internal architectural components that may be considered time-series-specific.
To start off, we use a model with the generic architecture of N-BEATS:
[6]:
model_name = "nbeats_run"
model_nbeats = NBEATSModel(
input_chunk_length=30,
output_chunk_length=7,
generic_architecture=True,
num_stacks=10,
num_blocks=1,
num_layers=4,
layer_widths=512,
n_epochs=100,
nr_epochs_val_period=1,
batch_size=800,
random_state=42,
model_name=model_name,
save_checkpoints=True,
force_reset=True,
**generate_torch_kwargs(),
)
[7]:
model_nbeats.fit(train_scaled, val_series=val_scaled)
[7]:
NBEATSModel(generic_architecture=True, num_stacks=10, num_blocks=1, num_layers=4, layer_widths=512, expansion_coefficient_dim=5, trend_polynomial_degree=2, dropout=0.0, activation=ReLU, input_chunk_length=30, output_chunk_length=7, n_epochs=100, nr_epochs_val_period=1, batch_size=800, random_state=42, model_name=nbeats_run, save_checkpoints=True, force_reset=True, pl_trainer_kwargs={'accelerator': 'cpu', 'callbacks': [<darts.utils.callbacks.TFMProgressBar object at 0x2b3d98fd0>]})
Let’s load the model from the checkpoint that performed best on the validation set.
[8]:
model_nbeats = NBEATSModel.load_from_checkpoint(model_name=model_name, best=True)
Let’s see the historical forecasts the model would have produced with an expanding training window, and a forecasting horizon of 7:
[9]:
pred_series = model_nbeats.historical_forecasts(
series_scaled,
start=val.start_time(),
forecast_horizon=7,
stride=7,
last_points_only=False,
retrain=False,
verbose=True,
)
pred_series = concatenate(pred_series)
[10]:
display_forecast(
pred_series,
series_scaled,
"7 day",
start_date=val.start_time(),
)
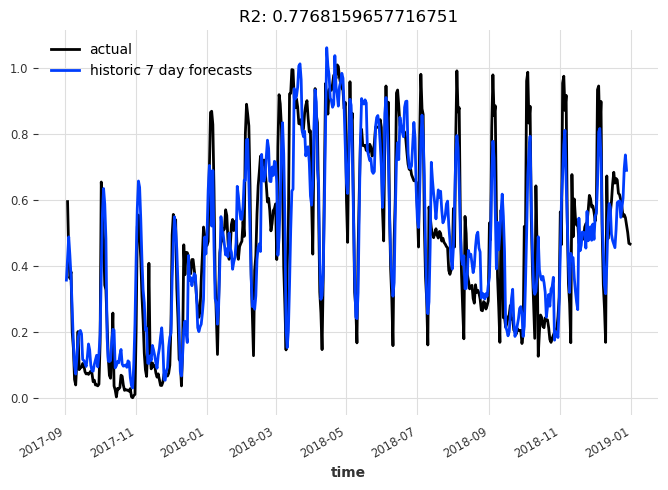
Interpretable model#
N-BEATS offers an interpretable architecture consisting of two stacks: A trend stack and a seasonality stack. The architecture is designed so that:
The trend component is removed from the input before it is fed into the seasonality stack
The partial forecasts of trend and seasonality are available as separate interpretable outputs
[11]:
model_name = "nbeats_interpretable_run"
model_nbeats = NBEATSModel(
input_chunk_length=30,
output_chunk_length=7,
generic_architecture=False,
num_blocks=3,
num_layers=4,
layer_widths=512,
n_epochs=100,
nr_epochs_val_period=1,
batch_size=800,
random_state=42,
model_name=model_name,
save_checkpoints=True,
force_reset=True,
**generate_torch_kwargs(),
)
[12]:
model_nbeats.fit(series=train_scaled, val_series=val_scaled)
[12]:
NBEATSModel(generic_architecture=False, num_stacks=30, num_blocks=3, num_layers=4, layer_widths=512, expansion_coefficient_dim=5, trend_polynomial_degree=2, dropout=0.0, activation=ReLU, input_chunk_length=30, output_chunk_length=7, n_epochs=100, nr_epochs_val_period=1, batch_size=800, random_state=42, model_name=nbeats_interpretable_run, save_checkpoints=True, force_reset=True, pl_trainer_kwargs={'accelerator': 'cpu', 'callbacks': [<darts.utils.callbacks.TFMProgressBar object at 0x2b3fc0790>]})
[13]:
model_nbeats = NBEATSModel.load_from_checkpoint(model_name=model_name, best=True)
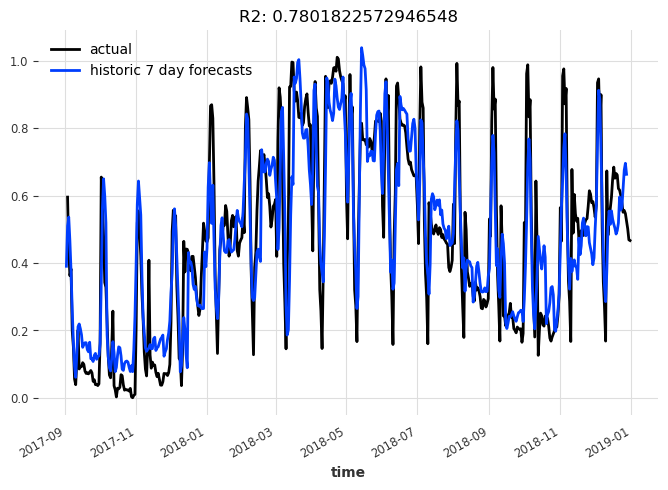
Let’s see the historical forecasts the model would have produced with an expanding training window, and a forecasting horizon of 7:
[14]:
pred_series = model_nbeats.historical_forecasts(
series_scaled,
start=val_scaled.start_time(),
forecast_horizon=7,
stride=7,
last_points_only=False,
retrain=False,
verbose=True,
)
pred_series = concatenate(pred_series)
[15]:
display_forecast(
pred_series, series_scaled, "7 day", start_date=val_scaled.start_time()
)
[ ]: