TimeSeries Deep Encoder#
This notebook walks through how to use Darts’ TiDEModel and benchmarks it against NHiTSModel.
TiDE (Time-series Dense Encoder) is a pure DL encoder-decoder architecture. It is special in that the temporal decoder can help mitigate the effects of anomalous samples on a forecast (Fig. 4 in the paper).
See the original paper and model description here: http://arxiv.org/abs/2304.08424.
[1]:
# fix python path if working locally
from utils import fix_pythonpath_if_working_locally
fix_pythonpath_if_working_locally()
%matplotlib inline
[2]:
%load_ext autoreload
%autoreload 2
%matplotlib inline
[ ]:
# use darts plotting style
from darts import set_option
set_option("plotting.use_darts_style", True)
[3]:
import warnings
import matplotlib.pyplot as plt
import pandas as pd
import torch
from pytorch_lightning.callbacks.early_stopping import EarlyStopping
from darts.dataprocessing.transformers.scaler import Scaler
from darts.datasets import AusBeerDataset
from darts.metrics import mae, mse
from darts.models import NHiTSModel, TiDEModel
warnings.filterwarnings("ignore")
import logging
logging.disable(logging.CRITICAL)
Model Parameter Setup#
Boilerplate code is no fun, especially in the context of training multiple models to compare performance. To avoid this, we use a common configuration that can be used with any Darts TorchForecastingModel.
A few interesting things about these parameters:
Gradient clipping: Mitigates exploding gradients during backpropagation by setting an upper limit on the gradient for a batch.
Learning rate: The majority of the learning done by a model is in the earlier epochs. As training goes on it is often helpful to reduce the learning rate to fine-tune the model. That being said, it can also lead to significant overfitting.
Early stopping: To avoid overfitting, we can use early stopping. It monitors a metric on the validation set and stops training once the metric is not improving anymore based on a custom condition.
[4]:
optimizer_kwargs = {
"lr": 1e-3,
}
# PyTorch Lightning Trainer arguments
pl_trainer_kwargs = {
"gradient_clip_val": 1,
"max_epochs": 200,
"accelerator": "auto",
"callbacks": [],
}
# learning rate scheduler
lr_scheduler_cls = torch.optim.lr_scheduler.ExponentialLR
lr_scheduler_kwargs = {
"gamma": 0.999,
}
# early stopping (needs to be reset for each model later on)
# this setting stops training once the the validation loss has not decreased by more than 1e-3 for 10 epochs
early_stopping_args = {
"monitor": "val_loss",
"patience": 10,
"min_delta": 1e-3,
"mode": "min",
}
#
common_model_args = {
"input_chunk_length": 12, # lookback window
"output_chunk_length": 12, # forecast/lookahead window
"optimizer_kwargs": optimizer_kwargs,
"pl_trainer_kwargs": pl_trainer_kwargs,
"lr_scheduler_cls": lr_scheduler_cls,
"lr_scheduler_kwargs": lr_scheduler_kwargs,
"likelihood": None, # use a likelihood for probabilistic forecasts
"save_checkpoints": True, # checkpoint to retrieve the best performing model state,
"force_reset": True,
"batch_size": 256,
"random_state": 42,
}
Data Loading and preparation#
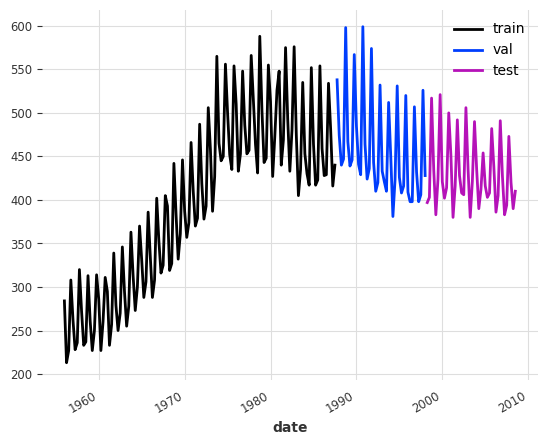
We consider the Australian quarterly beer sales in megaliters.
Before training, we split the data into train, validation, and test sets. The model will learn from the train set, use the validation set to determine when to stop training, and finally be evaluated on the test set.
To avoid leaking information from the validation and test sets, we scale the data based on the properties of the train set.
[5]:
series = AusBeerDataset().load()
train, temp = series.split_after(0.6)
val, test = temp.split_after(0.5)
[6]:
train.plot(label="train")
val.plot(label="val")
test.plot(label="test")
[7]:
scaler = Scaler() # default uses sklearn's MinMaxScaler
train = scaler.fit_transform(train)
val = scaler.transform(val)
test = scaler.transform(test)
Model configuration#
Using the already established shared arguments, we can see that the default parameters for NHiTS and TiDE are used. The only exception is that TiDE is tested both with and without Reversible Instance Normalization.
We then iterate through the model dictionary and train all of the models. When using early stopping it is important to save checkpoints. This allows us to continue past the best model configuration and then restore the optimal weights once training has been completed.
[8]:
# create the models
model_nhits = NHiTSModel(**common_model_args, model_name="hi")
model_tide = TiDEModel(
**common_model_args, use_reversible_instance_norm=False, model_name="tide0"
)
model_tide_rin = TiDEModel(
**common_model_args, use_reversible_instance_norm=True, model_name="tide1"
)
models = {
"NHiTS": model_nhits,
"TiDE": model_tide,
"TiDE+RIN": model_tide_rin,
}
[9]:
# train the models and load the model from its best state/checkpoint
for name, model in models.items():
# early stopping needs to get reset for each model
pl_trainer_kwargs["callbacks"] = [
EarlyStopping(
**early_stopping_args,
)
]
model.fit(
series=train,
val_series=val,
verbose=False,
)
# load from checkpoint returns a new model object, we store it in the models dict
models[name] = model.load_from_checkpoint(model_name=model.model_name, best=True)
[10]:
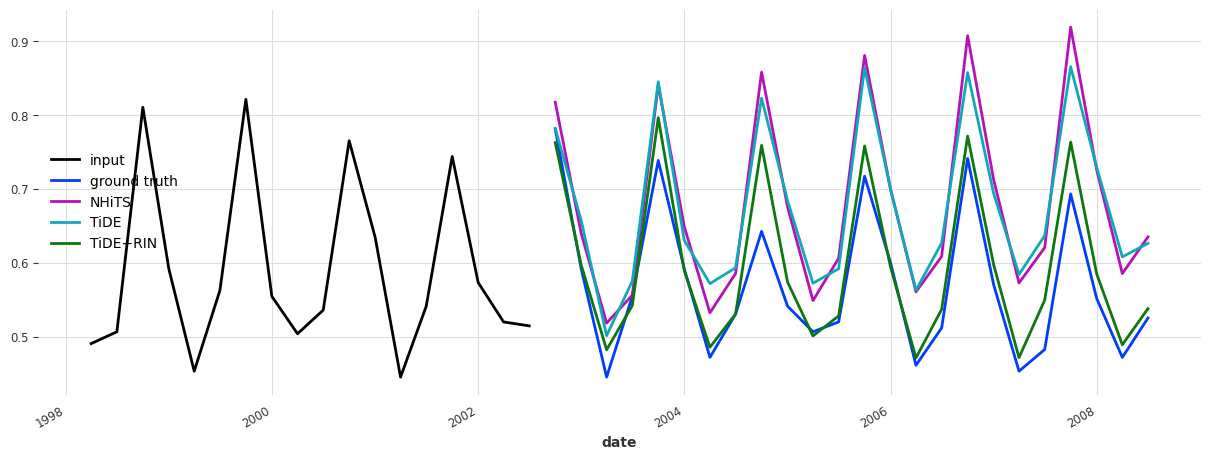
# we will predict the next `pred_steps` points after the end of `pred_input`
pred_steps = common_model_args["output_chunk_length"] * 2
pred_input = test[:-pred_steps]
fig, ax = plt.subplots(figsize=(15, 5))
pred_input.plot(label="input")
test[-pred_steps:].plot(label="ground truth", ax=ax)
result_accumulator = {}
# predict with each model and compute/store the metrics against the test sets
for model_name, model in models.items():
pred_series = model.predict(n=pred_steps, series=pred_input)
pred_series.plot(label=model_name, ax=ax)
result_accumulator[model_name] = {
"mae": mae(test, pred_series),
"mse": mse(test, pred_series),
}
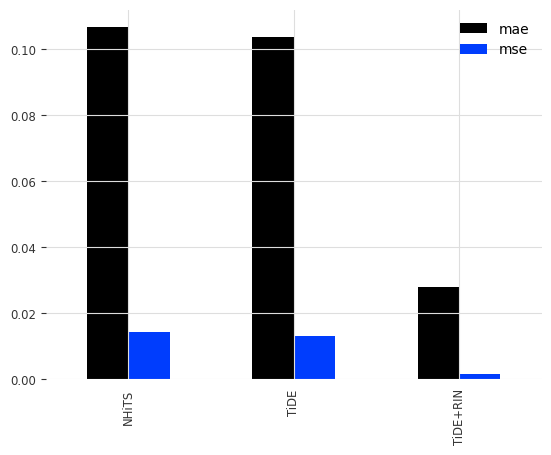
Results#
In this case, vanilla TiDE is similarly accurate as NHiTs. Including reversible instance normalization (RINorm) drastically helped to improve the TiDE forecasts (Keep in mind that this is just an example, and it is not always guaranteed to improve performance).
[11]:
results_df = pd.DataFrame.from_dict(result_accumulator, orient="index")
results_df.plot.bar()
[11]:
<Axes: >