Time Series Mixer (TSMixer)#
This notebook walks through how to use Darts’ TSMixerModel and benchmarks it against TiDEModel.
TSMixer (Time-series Mixer) is an all-MLP architecture for time series forecasting.
It does so by integrating historical time series data, future known inputs, and static contextual information. The architecture uses a combination of conditional feature mixing and mixer layers to process and combine these different types of data for effective forecasting.
Translated to Darts, this model supports all types of covariates (past, future, and/or static).
See the original paper and model description here.
According to the authors, the model outperforms several state-of-the-art models on multivariate forecasting tasks.
Let’s see how it performs against TideModel on the ETTh1 and ETTh2 datasets.
[1]:
# fix python path if working locally
from utils import fix_pythonpath_if_working_locally
fix_pythonpath_if_working_locally()
%matplotlib inline
[2]:
%load_ext autoreload
%autoreload 2
%matplotlib inline
[ ]:
# use darts plotting style
from darts import set_option
set_option("plotting.use_darts_style", True)
[3]:
import warnings
warnings.filterwarnings("ignore")
import logging
logging.disable(logging.CRITICAL)
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import torch
from pytorch_lightning.callbacks.early_stopping import EarlyStopping
from darts import concatenate
from darts.dataprocessing.transformers.scaler import Scaler
from darts.datasets import ETTh1Dataset, ETTh2Dataset
from darts.metrics import mql
from darts.models import TiDEModel, TSMixerModel
from darts.utils.callbacks import TFMProgressBar
from darts.utils.likelihood_models.torch import QuantileRegression
Data Loading and preparation#
We consider the ETTh1 and ETTh2 datasets which contain hourly multivariate data of an electricity transformer (load, oil temperature, …). You can find more information here.
We will add static information to each transformer time series, that identifies whether it is the ETTh1 or ETTh2 transformer. Both TSMixer and TiDE can levarage this information.
[4]:
series = []
for idx, ds in enumerate([ETTh1Dataset, ETTh2Dataset]):
trafo = ds().load().astype(np.float32)
trafo = trafo.with_static_covariates(pd.DataFrame({"transformer_id": [idx]}))
series.append(trafo)
series[0].to_dataframe()
[4]:
| component | HUFL | HULL | MUFL | MULL | LUFL | LULL | OT |
|---|---|---|---|---|---|---|---|
| date | |||||||
| 2016-07-01 00:00:00 | 5.827 | 2.009 | 1.599 | 0.462 | 4.203 | 1.340 | 30.531000 |
| 2016-07-01 01:00:00 | 5.693 | 2.076 | 1.492 | 0.426 | 4.142 | 1.371 | 27.787001 |
| 2016-07-01 02:00:00 | 5.157 | 1.741 | 1.279 | 0.355 | 3.777 | 1.218 | 27.787001 |
| 2016-07-01 03:00:00 | 5.090 | 1.942 | 1.279 | 0.391 | 3.807 | 1.279 | 25.044001 |
| 2016-07-01 04:00:00 | 5.358 | 1.942 | 1.492 | 0.462 | 3.868 | 1.279 | 21.948000 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 2018-06-26 15:00:00 | -1.674 | 3.550 | -5.615 | 2.132 | 3.472 | 1.523 | 10.904000 |
| 2018-06-26 16:00:00 | -5.492 | 4.287 | -9.132 | 2.274 | 3.533 | 1.675 | 11.044000 |
| 2018-06-26 17:00:00 | 2.813 | 3.818 | -0.817 | 2.097 | 3.716 | 1.523 | 10.271000 |
| 2018-06-26 18:00:00 | 9.243 | 3.818 | 5.472 | 2.097 | 3.655 | 1.432 | 9.778000 |
| 2018-06-26 19:00:00 | 10.114 | 3.550 | 6.183 | 1.564 | 3.716 | 1.462 | 9.567000 |
17420 rows × 7 columns
Before training, we split the data into train, validation, and test sets. The model will learn from the train set, use the validation set to determine when to stop training, and finally be evaluated on the test set.
[5]:
train, val, test = [], [], []
for trafo in series:
train_, temp = trafo.split_after(0.6)
val_, test_ = temp.split_after(0.5)
train.append(train_)
val.append(val_)
test.append(test_)
Lets look at the splits for the first column “HUFL” for each transformer
[6]:
show_col = "HUFL"
for idx, (train_, val_, test_) in enumerate(zip(train, val, test)):
train_[show_col].plot(label=f"train_trafo_{idx}")
val_[show_col].plot(label=f"val_trafo_{idx}")
test_[show_col].plot(label=f"test_trafo_{idx}")
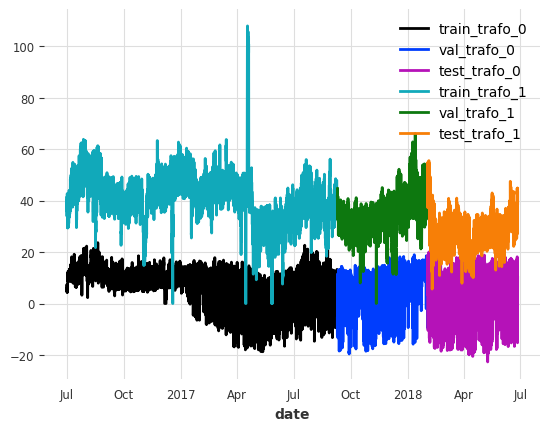
Now let’s scale the data. To avoid leaking information from the validation and test sets, we scale the data based on the properties of the train set.
[7]:
scaler = Scaler() # default uses sklearn's MinMaxScaler
train = scaler.fit_transform(train)
val = scaler.transform(val)
test = scaler.transform(test)
Model Parameter Setup#
Boilerplate code is no fun, especially in the context of training multiple models to compare performance. To avoid this, we use a common configuration that can be used with any Darts TorchForecastingModel.
A few interesting things about these parameters:
Gradient clipping: Mitigates exploding gradients during backpropagation by setting an upper limit on the gradient for a batch.
Learning rate: The majority of the learning done by a model is in the earlier epochs. As training goes on it is often helpful to reduce the learning rate to fine-tune the model. That being said, it can also lead to significant overfitting.
Early stopping: To avoid overfitting, we can use early stopping. It monitors a metric on the validation set and stops training once the metric is not improving anymore based on a custom condition.
Likelihood and Loss Functions: You can either make the model probabilistic with a
likelihood, or deterministic with aloss_fn. In this notebook we train probabilistic models using QuantileRegression.Reversible Instance Normalization: Use Reversible Instance Normalization which in most of the cases improves model performance.
Encoders: We can encode time axis/calendar information and use them as past or future covariates using
add_encoders. Here, we’ll add cyclic encodings of the hour, day of the week, and month as future covariates
[8]:
def create_params(
input_chunk_length: int,
output_chunk_length: int,
full_training=True,
):
# early stopping: this setting stops training once the the validation
# loss has not decreased by more than 1e-5 for 10 epochs
early_stopper = EarlyStopping(
monitor="val_loss",
patience=10,
min_delta=1e-5,
mode="min",
)
# PyTorch Lightning Trainer arguments (you can add any custom callback)
if full_training:
limit_train_batches = None
limit_val_batches = None
max_epochs = 200
batch_size = 256
else:
limit_train_batches = 20
limit_val_batches = 10
max_epochs = 40
batch_size = 64
# only show the training and prediction progress bars
progress_bar = TFMProgressBar(
enable_sanity_check_bar=False, enable_validation_bar=False
)
pl_trainer_kwargs = {
"gradient_clip_val": 1,
"max_epochs": max_epochs,
"limit_train_batches": limit_train_batches,
"limit_val_batches": limit_val_batches,
"accelerator": "auto",
"callbacks": [early_stopper, progress_bar],
}
# optimizer setup, uses Adam by default
# optimizer_cls = torch.optim.Adam
optimizer_kwargs = {
"lr": 1e-4,
}
# learning rate scheduler
lr_scheduler_cls = torch.optim.lr_scheduler.ExponentialLR
lr_scheduler_kwargs = {"gamma": 0.999}
# for probabilistic models, we use quantile regression, and set `loss_fn` to `None`
likelihood = QuantileRegression()
loss_fn = None
return {
"input_chunk_length": input_chunk_length, # lookback window
"output_chunk_length": output_chunk_length, # forecast/lookahead window
"use_reversible_instance_norm": True,
"optimizer_kwargs": optimizer_kwargs,
"pl_trainer_kwargs": pl_trainer_kwargs,
"lr_scheduler_cls": lr_scheduler_cls,
"lr_scheduler_kwargs": lr_scheduler_kwargs,
"likelihood": likelihood, # use a `likelihood` for probabilistic forecasts
"loss_fn": loss_fn, # use a `loss_fn` for determinsitic model
"save_checkpoints": True, # checkpoint to retrieve the best performing model state,
"force_reset": True,
"batch_size": batch_size,
"random_state": 42,
"add_encoders": {
"cyclic": {
"future": ["hour", "dayofweek", "month"]
} # add cyclic time axis encodings as future covariates
},
}
Model configuration#
Let’s use the last week of hourly data as lookback window (input_chunk_length) and train a probabilistic model to predict the next 24 hours directly (output_chunk_length). Additionally, we tell the model to use the static information. To keep the notebook simple, we’ll set full_training=False. To get even better performance, set full_training=True.
Apart from that, we use our helper function to set up all the common model arguments.
[9]:
input_chunk_length = 7 * 24
output_chunk_length = 24
use_static_covariates = True
full_training = False
[10]:
# create the models
model_tsm = TSMixerModel(
**create_params(
input_chunk_length,
output_chunk_length,
full_training=full_training,
),
use_static_covariates=use_static_covariates,
model_name="tsm",
)
model_tide = TiDEModel(
**create_params(
input_chunk_length,
output_chunk_length,
full_training=full_training,
),
use_static_covariates=use_static_covariates,
model_name="tide",
)
models = {
"TSM": model_tsm,
"TiDE": model_tide,
}
Model Training#
Now let’s train all of the models. When using early stopping it is important to save checkpoints. This allows us to continue past the best model configuration and then restore the optimal weights once training has been completed.
[11]:
# train the models and load the model from its best state/checkpoint
for model_name, model in models.items():
model.fit(
series=train,
val_series=val,
)
# load from checkpoint returns a new model object, we store it in the models dict
models[model_name] = model.load_from_checkpoint(
model_name=model.model_name, best=True
)
Backtest the probabilistic models#
Let’s configure the prediction. For this example, we will:
generate historical forecasts on the test set using the pre-trained models. Each forecast covers a 24 hour horizon, and the time between two consecutive forecasts is also 24 hours. This will give us 276 multivariate forecasts per transformer to evaluate the model!
generate 500 stochastic samples for each prediction point (since we have trained probabilistic models)
evaluate/backtest the probabilistic historical forecasts for some quantiles using the Mean Quantile Loss (
mql()).
And we’ll create some helper functions to generate the forecasts, compute the backtest, and to visualize the predictions.
[12]:
# configure the probabilistic prediction
num_samples = 500
forecast_horizon = output_chunk_length
# compute the Mean Quantile Loss over these quantiles
evaluate_quantiles = [0.05, 0.1, 0.2, 0.5, 0.8, 0.9, 0.95]
def historical_forecasts(model):
"""Generates probabilistic historical forecasts for each transformer
and returns the inverse transformed results.
Each forecast covers 24h (forecast_horizon). The time between two forecasts
(stride) is also 24 hours.
"""
hfc = model.historical_forecasts(
series=test,
forecast_horizon=forecast_horizon,
stride=forecast_horizon,
last_points_only=False,
retrain=False,
num_samples=num_samples,
verbose=True,
)
return scaler.inverse_transform(hfc)
def backtest(model, hfc, name):
"""Evaluates probabilistic historical forecasts using the Mean Quantile
Loss (MQL) over a set of quantiles."""
# add metric specific kwargs
metric_kwargs = [{"q": q} for q in evaluate_quantiles]
metrics = [mql for _ in range(len(evaluate_quantiles))]
bt = model.backtest(
series=series,
historical_forecasts=hfc,
last_points_only=False,
metric=metrics,
metric_kwargs=metric_kwargs,
verbose=True,
)
bt = pd.DataFrame(
bt,
columns=[f"q_{q}" for q in evaluate_quantiles],
index=[f"{trafo}_{name}" for trafo in ["ETTh1", "ETTh2"]],
)
return bt
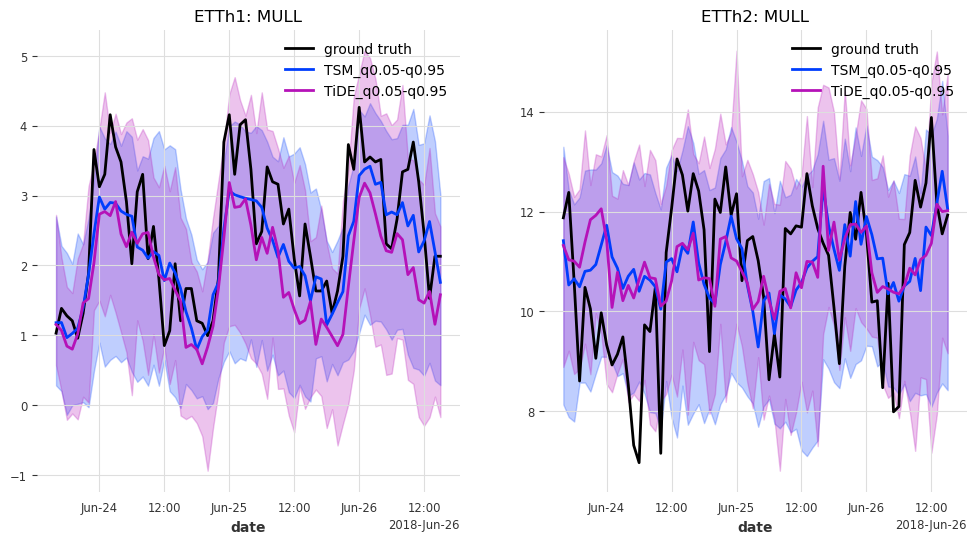
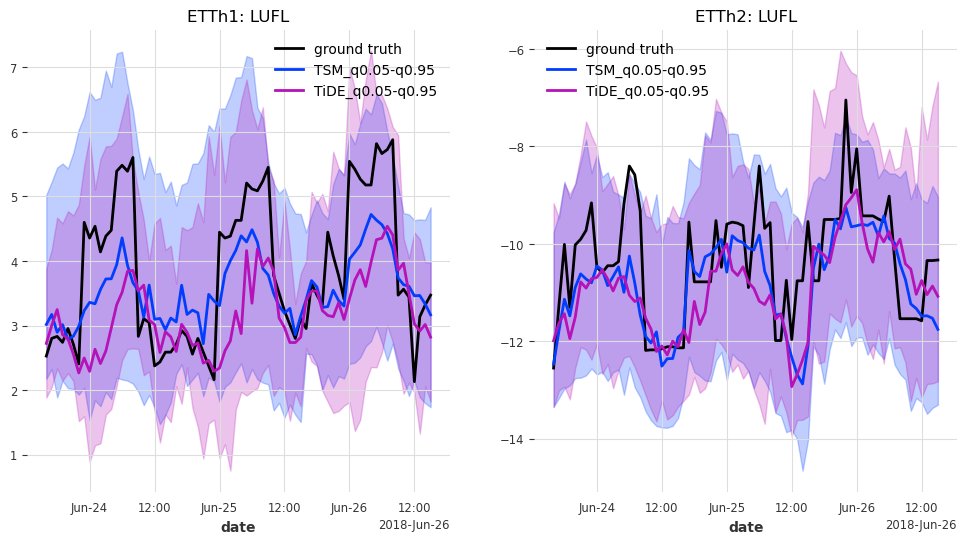
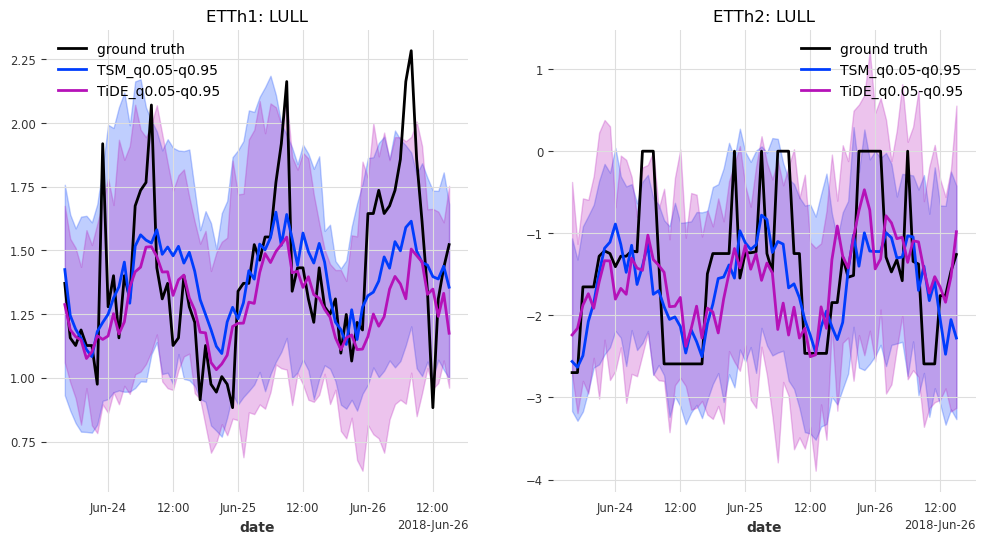
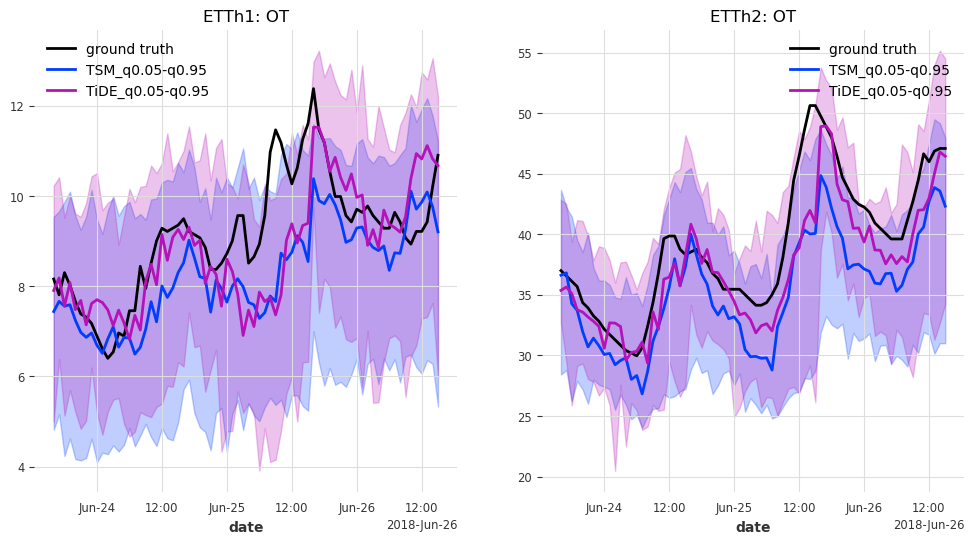
def generate_plots(n_days, hfcs):
"""Plot the probabilistic forecasts for each model, transformer and transformer
feature against the ground truth."""
# concatenate historical forecasts into contiguous time series
# (works because forecast_horizon=stride)
hfcs_plot = {}
for model_name, hfc_model in hfcs.items():
hfcs_plot[model_name] = [
concatenate(hfc_series[-n_days:], axis=0) for hfc_series in hfc_model
]
# remember start and end points for plotting the target series
hfc_ = hfcs_plot[model_name][0]
start, end = hfc_.start_time(), hfc_.end_time()
# for each target column...
for col in series[0].columns:
fig, axes = plt.subplots(ncols=2, figsize=(12, 6))
# ... and for each transformer...
for trafo_idx, trafo in enumerate(series):
trafo[col][start:end].plot(label="ground truth", ax=axes[trafo_idx])
# ... plot the historical forecasts for each model
for model_name, hfc in hfcs_plot.items():
hfc[trafo_idx][col].plot(
label=model_name + "_q0.05-q0.95", ax=axes[trafo_idx]
)
axes[trafo_idx].set_title(f"ETTh{trafo_idx + 1}: {col}")
plt.show()
Okay, now we’re ready to evaluate the models
[13]:
bts = {}
hfcs = {}
for model_name, model in models.items():
print(f"Model: {model_name}")
print("Generating historical forecasts..")
hfcs[model_name] = historical_forecasts(models[model_name])
print("Evaluating historical forecasts..")
bts[model_name] = backtest(models[model_name], hfcs[model_name], model_name)
Model: TSM
Generating historical forecasts..
Evaluating historical forecasts..
Model: TiDE
Generating historical forecasts..
Evaluating historical forecasts..
Let’s see how they performed.
Note: These results are likely to improve/change when setting
full_training=True
[14]:
bt_df = pd.concat(bts.values(), axis=0).sort_index()
bt_df
[14]:
| q_0.05 | q_0.1 | q_0.2 | q_0.5 | q_0.8 | q_0.9 | q_0.95 | |
|---|---|---|---|---|---|---|---|
| ETTh1_TSM | 0.501772 | 0.769545 | 1.136141 | 1.568439 | 1.098847 | 0.721835 | 0.442062 |
| ETTh1_TiDE | 0.573716 | 0.885452 | 1.298672 | 1.671870 | 1.151501 | 0.727515 | 0.446724 |
| ETTh2_TSM | 0.659187 | 1.030655 | 1.508628 | 1.932923 | 1.317960 | 0.857147 | 0.524620 |
| ETTh2_TiDE | 0.627251 | 0.982114 | 1.450893 | 1.897117 | 1.323661 | 0.862239 | 0.528638 |
The backtest gives us the Mean Quantile Loss for the selected quantiles over all transformer features per transformer and model. The lower the value, the better. The q_0.5 is identical to the Mean Absolute Error (MAE) between the median prediction and the ground truth.
Both models seem to have performed comparably well. And how does it look on average over all quantiles?
[15]:
bt_df.mean(axis=1)
[15]:
ETTh1_TSM 0.891234
ETTh1_TiDE 0.965064
ETTh2_TSM 1.118732
ETTh2_TiDE 1.095988
dtype: float64
Here the results are also very similar. It seems that TSMixer performed better for ETTh1, and TiDEModel for ETTh2.
And last but not least, let’s have look at the predictions for the last n_days=3 days in the test set.
Note: The prediction intervals are expected to get narrower when
full_training=True
[16]:
generate_plots(n_days=3, hfcs=hfcs)
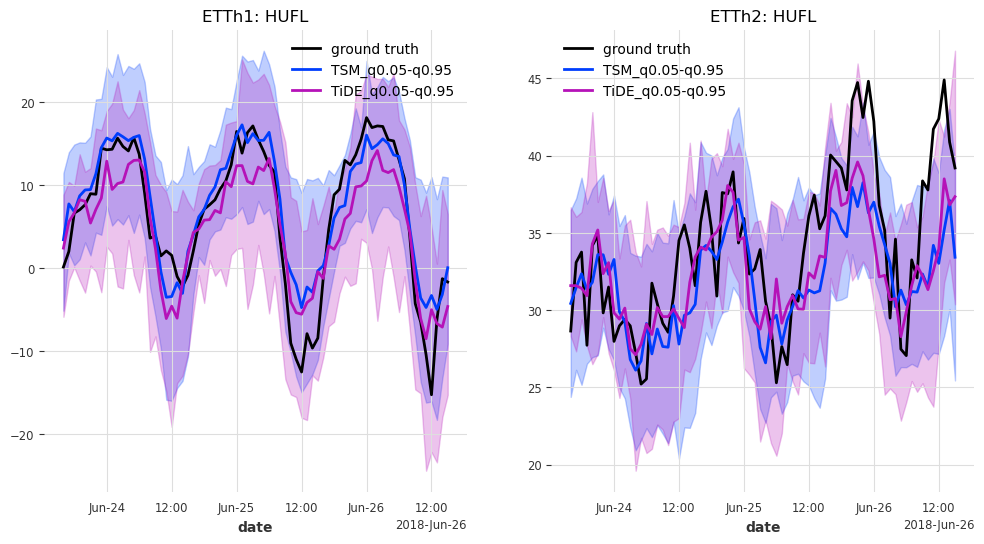
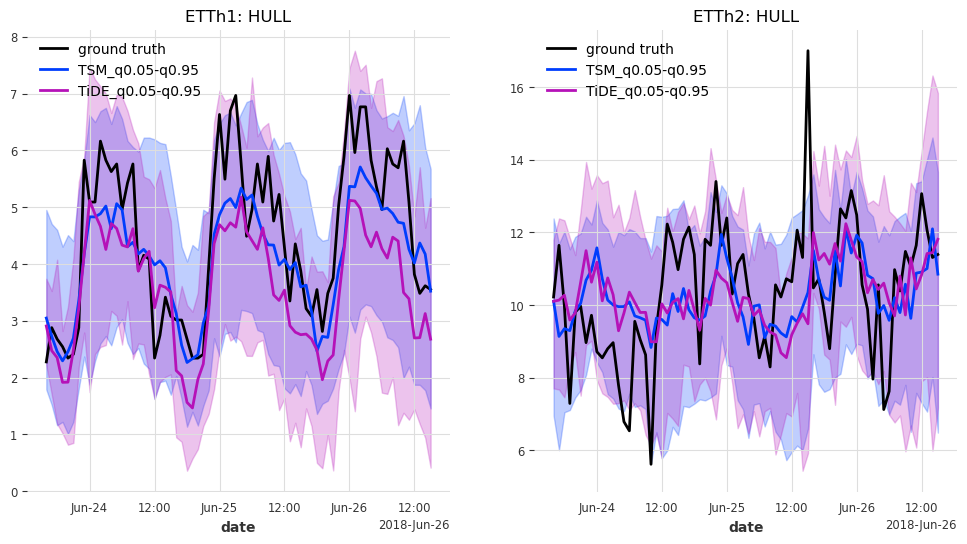
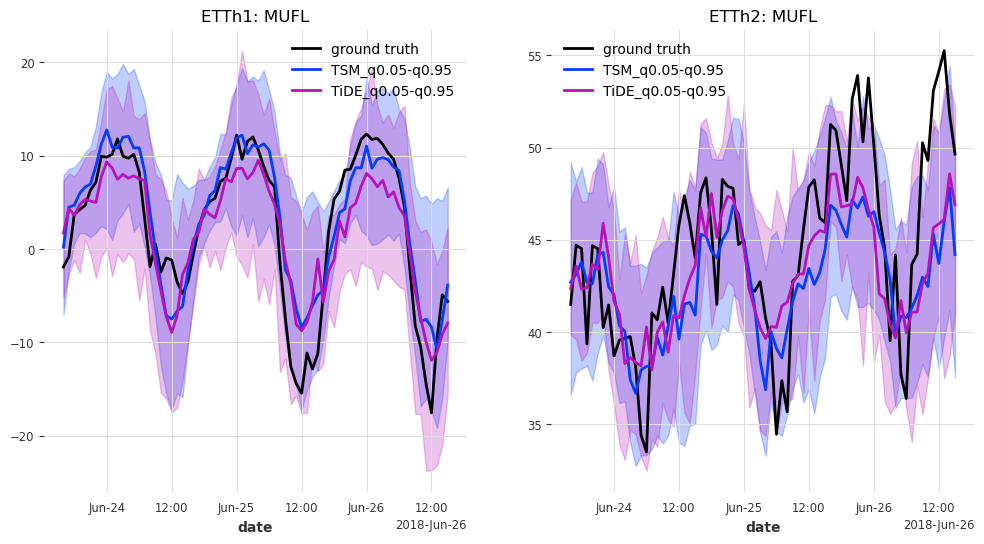
Results#
In this case, TSMixer and TiDEModel both perform similarly well. Keep in mind that we performed only partial training on the data, and that we used the default model parameters without any hyperparameter tuning.
Here are some ways to further improve the performance:
set
full_training=Trueperform hyperparameter tuning
add more covariates (we have only added cyclic encodings of calendar information)
…
[ ]: